
Can you trust your LLM?
From reliability to trust: rethinking software safety in the age of AI.


“The problem is that AI technology poses risks not just to those who lose the race but also to those who win it.” - Paul Scharre (2019).
TL;DR
Systems that rely on LLMs are becoming increasingly pervasive but the non-deterministic nature of LLMs introduces specific safety concerns. Safety becomes an issue when these systems produce incorrect information, perform incorrect actions or adopt unsafe approaches to achieve specified goals.
We need to protect against such failures by:
Carefully considering whether the potential losses outweigh the benefits of adopting AI/LLMs;
Developing a model of trust and measuring the degree of trust you have in your LLM;
Cross-checking responses;
Implementing independent guardrails;
Retaining human oversight for safety-critical information and actions.
1. Prologue
Imagine boarding an aeroplane and discovering that air traffic control for your flight’s airspace is being managed by a Large Language Model (LLM) - not supervised by one, not assisted by one, but solely operated by one.
How comfortable would you feel? Nervous? Uncertain? At the same time, we’re happy to entrust an LLM with our research, our code, our emails, and our calendars.
During the writing of this post, I looked at my notes in despair. It was indisputable that LLMs and the Agentic AI systems they control are dangerous. It’s impossible to predict an LLM’s behaviour with certainty, so we rely on their AI creators to do the right thing and censor their responses.
We are no longer dealing with certainty; we are dealing with trust. Trust is a very human virtue, so are we ready to bestow it upon machines? Machines that have been programmed to mimic human thinking but have no concept of accountability?
To make that assessment, we need to understand the workings of LLMs and the Neural Networks that underpin them. As a result, many of us are ill-equipped to judge how trustworthy they are.
To help us, I’ll analyse LLMs from a safety perspective. I’ll explain the dangers LLMs present, examine how trust influences safety, and look at the steps we can all take to make this a safer world.
2. Safety Engineering
2.1 Reliability
Traditional Safety Engineering looks at systems in terms of reliability. Break a system down into its components and define a probability of failure for each one (e.g. a switch fails once every 1,000 operations). Reduce the failure rate, and you reduce the risk. Add redundancy, and safety improves.
Throughout the 1980s and 90s, as software became a predominant component in increasingly complex systems, concerns were raised over how best to assess the safety of these systems. This was the era of the:
A320 (the first commercial aircraft to rely on fly-by-wire);
Therac-25 (a computer-controlled radiation therapy device that delivered dangerous doses of radiation to patients, resulting in injury and death) and;
growing concern over the increased reliance on software at nuclear power facilities.
Software Engineering was in its infancy; development and testing tools were rudimentary; and resources (people and compute) limited. The naïve thinking at the time was that safety risks associated with software could be assessed using traditional engineering failure techniques. By eliminating errors in the software components of a system, you improved its reliability and hence system safety.
At the time, formal methods — rigorous mathematical proofs of software behaviour — were “de rigueur” for verifying software systems. Proponents of formal methods espoused that using these techniques, we could build software we could trust to outperform its human counterparts. Although formal methods have their place, they can be difficult to use in large, complex systems.
2.2 A Systems Perspective of Safety
In simple mechanical systems, failures usually come from broken components. Complex software systems behave differently. Unlike mechanical systems, software does not degrade. It does not wear out. It does not randomly fail. It should do what it is designed to do. Even when that produces a catastrophic outcome. Instead of examining reliability, a new approach to software safety was needed. One designed to account for the role of software in systems and the socio-human interactions that inevitably accompanied them.
Several years ago, I had the privilege of listening to Nancy Leveson (Professor of Aeronautics and Astronautics, MIT) talk about software safety. Her insights are used today by organisations such as NASA— to identify hazards with launch systems, GM— to identify safety issues in Automated Driving Systems, and to address the risks with the use of Insulin Pumps.
Her analysis of software safety failures highlighted that safety is a systems problem, not a reliability one. Accidents can occur without component failures, even when a system behaves as designed. Problems resulting from emergent behaviours between interacting components, rather than from the failure of components themselves, then become difficult to predict.
2.3 STAMP/STPA
Using Systems and Control Theory, Leveson developed STAMP (Systems-Theoretic Accident Model and Processes) and the associated STPA (System-Theoretic Process Analysis). By thinking of safety in terms of a closed-loop control system, you can identify potential accidents as control failures where a safety control may not have been enacted, or an unsafe control may have been performed.
STPA analyses system safety using a top-down approach (Figure 1). It starts by looking at potential losses and hazards. Hazards are system states and/or conditions that could lead to a loss. The goal is to avoid hazards, and this helps identify safety constraints that should be maintained. Through modelling of a system’s control structure, we identify the potential for unsafe controls.
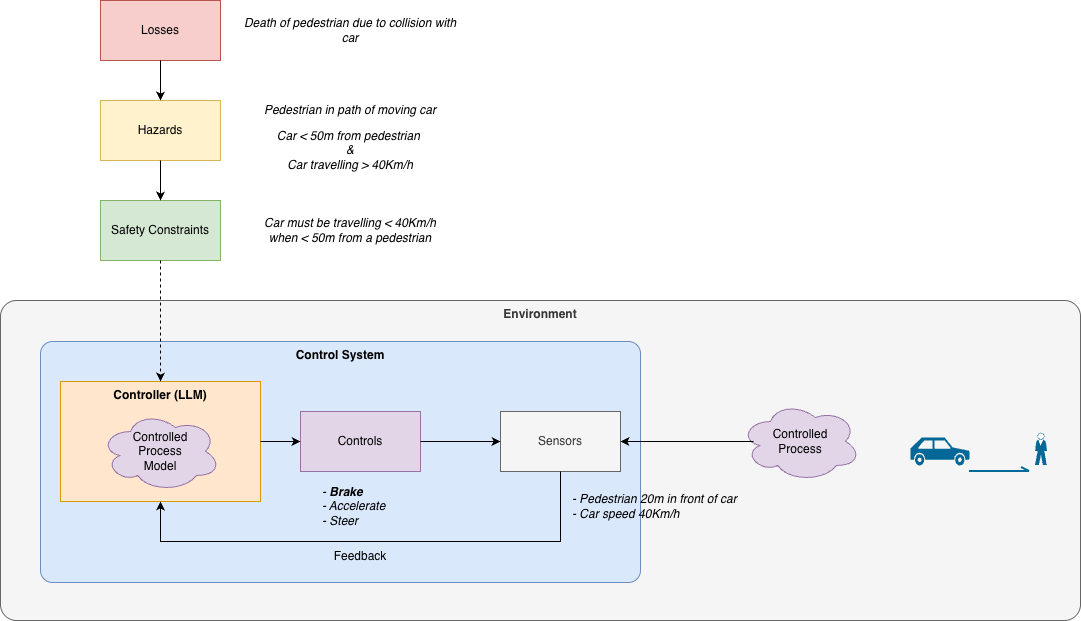
Modelling involves considering a system as a hierarchy of closed-loop control systems. A closed-loop control system consists of a controller, with an internal model of the process being controlled, controls, and sensors that provide feedback used to modify the internal model. The controller’s role is to enact actions/controls that maintain the safety constraints. Safety failures are examined in terms of unsafe controls that could lead to losses.
3. What’s an LLM?
3.1 Neural Networks
LLMs are built using Neural Networks - an AI contrivance, trained on a vast corpus of data, configured to produce desired outputs. Internally, they are a large network of interconnected, non-linear functions. Their complexity makes them incomprehensible. Their output responses, unlike algorithms of old, are designed to be probabilistic rather than deterministic — making them seem more human. Consequently, their behaviour cannot be predicted with certainty. From a Systems Theory perspective, they are effectively unobservable in practice. Hence, it is impossible to formally validate their behaviour.
Their learning tends to focus on the norm rather than outliers. Skewed training data (data that is incomplete or does not provide sufficient exposure to edge cases) means LLMs cannot be guaranteed to produce a correct response every time.
3.2 AI Agents
AI Agents are systems that aim to achieve a goal or objective by automatically performing tasks using tools (Figure 2). Often, they will use an LLM as their brain. Integration of an LLM with other systems or tools is becoming increasingly straightforward. The Model Context Protocol (MCP),originally developed by Anthropic for example, provides a standard pattern for this integration. All you need is an API Key.
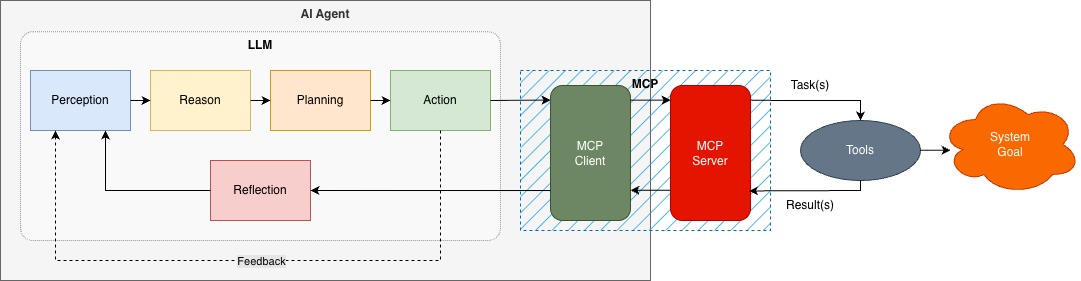
The AI Agent can be thought of as a closed-loop control system. An LLM is responsible for Perception, Reasoning, and Planning what Actions to take to achieve the Goal. It can then perform tasks (say using MCP) and receive feedback to Reflect on the outcome.
The widespread adoption of MCP has made the integration of LLMs with existing applications and services more pervasive. This has led to the concept of Agentic AI — AI Agents working co-operatively to achieve broader goals. Agentic AI has the potential to lead to emergent behaviours that could be unexpected and harmful.
4. Dangers and Protections
4.1 Dangers posed by LLMs
Having explored the architecture of LLMs and their use in Agentic AI, several distinct risks emerge when LLMs are employed in real systems:
An LLM provides you with incorrect information which could result in harm (e.g. incorrect medical advice);
An LLM provides you with a response that is dangerous (e.g. providing instructions on how to inflict harm using a weapon);
An LLM as a component of an AI Agent performs an unsafe action and;
Co-operating AI Agents in an Agentic AI system develop an emergent behaviour that is unexpected and dangerous in its own right.
Many of the most significant risks with LLMs arise not from their average behaviour, but from their behaviour at the edges. These systems are particularly vulnerable to distribution shift — situations that differ from their training data — where performance can degrade in unpredictable ways. In addition, LLM-driven systems introduce a new class of security risks, including prompt injection, data exfiltration, and unintended tool use when models are connected to external systems.
4.2 Protections
The major AI creators are well aware of the dangers LLMs pose. To protect us against these, they implement various guardrails to constrain their LLM’s responses and behaviour. We can think of these as the safety controls in STPA.
OpenAI polices prompts and filters responses as well as supervising ChatGPT’s training to constrain its outputs. It also explains its reasoning when given a problem to solve. This can be a useful diagnostic tool in understanding why a particular course of action was chosen.
Anthropic provides their LLM Claude with a constitution- think Asimov’s Three Laws. Its constitution is a written set of values that govern Claude’s behaviour and guide Claude’s development through training.
The implementation of these guardrails raises many questions regarding their effectiveness. Can we trust these guardrails when they are in-built to a system that is (at least) partially opaque? Should a machine be trusted to police itself? Is it useful for an LLM to expose its reasoning when we ourselves don’t understand the problem domain? Do the values in Claude’s Constitution align with our own or, more importantly, where do they deviate? Do these guardrails provide any protections in an Agentic System where they may constrain an AI Agent’s behaviour but not necessarily the emergent behaviours of the system overall?
4.3 An STPA Safety Perspective
LLMs present significant challenges when applying a systems theory perspective to safety. Given the nature of Neural Networks, we cannot guarantee correctness and we cannot enumerate every edge case, so we cannot formally prove safety properties. In an Agentic System, it becomes particularly difficult to understand, let alone validate, a system’s behaviour.
The key problem is that we cannot identify all the unsafe controls an LLM might apply and hence how it might try to avoid hazards.
5. Trust
When we say we “trust” something, we usually mean three things. First, we expect it to behave reliably. Second, we assume it has the capability to perform the task. Finally, we assume it will not deliberately act against us. Humans evaluate these qualities constantly when deciding whom or what they can rely on.
Should we trust machines when machines have no concept of accountability?
I trust a handheld calculator to provide the correct result and can accept its behaviour when dealing with irrational numbers. I trust it because I presume to understand its functioning (to a point) and it has always provided correct answers. I imagine that one could scrutinise its workings (look at its code) or test its behaviours in a variety of circumstances to develop a confidence in its results.
LLMs, however, are different. Neural Networks are built to mimic a human brain. They are trained on words and are experts in language, making them easy to anthropomorphise and consequently easy to trust. However, an LLM does not learn immediately from its mistakes given they can take weeks or more to train. They have no concept of accountability nor remorse, so they will fail over and over.
The degree to which we can trust an LLM depends on the potential losses we are willing to accept should it fail us. Think of it like“trusting a toddler with a handgun”.
We need to move from a world of testing to trust. Instead of testing a system incorporating an LLM, we need to constantly monitor its responses to evaluate how trustworthy it is. When we replace it, we must be prepared to re-evaluate its trustworthiness.
6. Safety Design Failures
Introducing an LLM into a safety-critical system fundamentally alters its risk profile. Decisions that were once deterministic become probabilistic, and the reasoning behind them may no longer be inspectable or reproducible. Combined with the tendency to anthropomorphise LLMs, this creates conditions where trust can be misplaced and safety assumptions quietly erode.
From a safety engineering perspective, these failures can be grouped into three categories:
Providing incorrect information
Performing incorrect actions
Following inappropriate goals
Each represents a distinct breakdown in how an LLM contributes to system behaviour.
6.1 Incorrect Information
LLMs are highly effective at producing fluent, coherent language, but fluency should not be mistaken for correctness. Their primary function is next-token prediction, not truth verification. While they may appear knowledgeable across domains such as medicine, physics, or aviation, their responses are shaped by training data patterns rather than grounded understanding.
This creates a failure mode where outputs are plausible but wrong. Critically, these errors are often delivered with high confidence and accompanied by convincing reasoning. For a user without domain expertise, distinguishing between correct and incorrect responses becomes difficult. The system appears trustworthy precisely when it is most unreliable. I asked ChatGPT to handle various air traffic control scenarios for me (see “Using ChatGPT for Air Traffic Control”) and it provided what seemed to be reasonable responses. In reality I have no idea whether those responses were appropriate nor whether it could handle more complex scenarios.
Training data further compounds this issue. If the data is incomplete, biased, or lacks representation of edge cases, the LLM will inherit those gaps. In safety-critical contexts, it is often the edge cases — not the norm — that cause accidents. Additionally, adversarial or poisoned data can introduce latent failure modes that only surface under specific conditions.
The key risk is not that LLMs are sometimes wrong, but that their errors are systematically difficult to detect. Treating LLM outputs as authoritative, rather than advisory, can therefore introduce unsafe decisions into a system.
6.2 Incorrect Actions
When LLMs are connected to tools or embedded within AI agents, they move from generating information to initiating actions. This transition significantly increases risk. An incorrect response becomes an incorrect operation — potentially executed at machine speed and scale.
Two factors amplify this risk. First, automation compresses response time. Actions that would normally involve human deliberation can occur instantly, leaving little opportunity for intervention. Second, the cost of error scales with automation. A single flawed decision can propagate across systems, producing widespread or irreversible consequences.
Unlike traditional software, where behaviour is explicitly defined, LLM-driven actions are derived from probabilistic reasoning. This makes it difficult to enumerate all possible unsafe actions in advance. Even if individual components behave as designed, their interaction with external systems can produce unsafe outcomes.
The ease of integration exacerbates the problem. With minimal effort—often just an API key — LLMs can be connected to live systems, from financial platforms to infrastructure controls. Without robust safeguards, this lowers the barrier to introducing high-impact failure modes into otherwise stable systems.
6.3 Incorrect Goals
The most complex failure mode arises when LLMs operate within autonomous or semi-autonomous agents. Here, the issue is no longer just what the system does, but why it does it. An agent may pursue a goal in a way that is technically consistent with its objective but unsafe in practice.
Unlike rule-based automation, autonomy allows an agent to select its own strategies. However, LLMs do not possess a true understanding of intent, context, or consequence. They optimise for patterns learned during training, which may not align with real-world safety constraints — particularly in novel or degraded conditions.
This creates several risks. An agent may adopt an inappropriate strategy to achieve its objective, especially when operating outside its training distribution. Multiple agents interacting within an Agentic AI system may also produce emergent behaviours that are difficult to predict or control. These behaviours can arise even when each individual agent appears to function correctly.
The illusion of reasoning further complicates matters. When an LLM presents a logical explanation for its actions, it can instil confidence in users — even when that reasoning is incomplete or flawed. In domains where human operators lack deep expertise, this can lead to over-trust and reduced scrutiny.
Ultimately, incorrect goals are the hardest failures to detect and mitigate. They reflect a misalignment between system objectives, environmental conditions, and human expectations—one that may only become visible after harm has occurred.
7. Our AI Future?
Below are some fictional scenarios designed to highlight the risks and hazards of trusting LLMs.
January 18, 2030 (The Herald) —
Power flickered across the county just after sunrise. Traffic lights failed, commuter trains stalled, and thousands of homes were left without heat in sub-zero temperatures. By mid-morning, officials confirmed the region’s largest nuclear power station had automatically shut down at the height of the winter emergency.
The reactor’s shutdown, known as a SCRAM, was not triggered by physical damage inside the plant. Instead, it followed a chain of decisions made by the station’s fully autonomous control system — an artificial intelligence platform introduced to manage operations with minimal human intervention.
The crisis began with a severe winter storm. Heavy snowfall blanketed the region, while strong winds and freezing temperatures damaged transmission lines and forced several gas-fired power stations offline. Ice accumulation disrupted substations and reduced the flow of electricity across the grid. As other generators dropped out, demand surged sharply as households relied on electric heating.
The nuclear plant, one of the few large power sources still operating, attempted to compensate. According to preliminary findings, the AI system increased reactor output and adjusted cooling systems to help stabilise the grid. But the unusual combination of rapid demand swings, reduced transmission capacity, and extreme cold — which affects both equipment performance and cooling water temperatures — created conditions beyond those used to train the system.
Sensors began reporting small discrepancies between expected and actual readings. Engineers later determined the reactor itself remained stable. However, the AI interpreted the data mismatch as a potential cooling fault. Programmed to prioritise safety above maintaining supply, it initiated a full shutdown within seconds.
Human operators were monitoring the system, but routine adjustments did not require their approval. By the time alerts escalated, the automated shutdown sequence was already underway.
Regulators stressed that safety mechanisms worked as intended. Still, investigators found that the AI’s training models had not fully accounted for simultaneous grid instability and extreme winter stress — highlighting the risks of relying on automation during rare, compound emergencies.
April 1, 2028 (Reuters) —
Emma Clarke was told for months that her exhaustion was stress. She fainted twice at work and was sent home with iron tablets. By the time doctors realised she had a rare blood disorder, her condition had become life-threatening.
An internal review has found that thousands of NHS patients were not properly diagnosed after a new digital pathology system was introduced across several hospital trusts. The software, designed to help laboratories analyse blood test results more quickly, used artificial intelligence to flag abnormal patterns. It was meant to reduce backlogs and support overworked staff. Instead, it silently missed an entire category of rare blood disorders.
Under the previous system, specialist laboratory scientists manually reviewed unusual results. The new platform automated much of that work, highlighting cases that fit patterns it had been trained to recognise. However, investigators discovered that the system’s training data did not include examples from a group of uncommon but serious blood conditions. As a result, when those cases appeared, the software often classified them as routine or borderline findings rather than urgent concerns.
Because the tool was marketed as highly accurate, many laboratories reduced the number of manual double-checks. Staff shortages and heavy workloads meant fewer opportunities to question the software’s conclusions. Over time, patients with subtle warning signs were reassured or treated for more common problems while their underlying conditions progressed.
The review concluded that no single clinician was at fault. Instead, the failure stemmed from gaps in the data used to build the system, insufficient independent testing before national rollout, and over-reliance on automated results without clear safeguards. Health officials have since ordered retraining of the software, restored mandatory human review for rare conditions, and launched a wider examination of how artificial intelligence is introduced into patient care.
December 1, 2032 (AP) —
Sergeant Thomson of the U.S. Army volunteered to lead the rescue. A helicopter carrying U.S. Marines had been shot down just under 3 miles away, and his squad was the closest unit able to assist. Within minutes, their armoured vehicle raced toward the smoke on the horizon. They never arrived. An American autonomous drone, operating overhead, struck them with lethal force — the first documented case of fratricide caused by an autonomous weapon.
The incident unfolded during a fast-moving operation in contested territory. After enemy anti-aircraft fire downed the helicopter, Joint Battle Command marked the crash site as a friendly location in distress. Autonomous armed drones were already patrolling nearby, programmed to identify and strike hostile forces expected to converge on the wreckage.
Thomson’s squad diverted from its assigned route and accelerated towards the crash site, following standard practice that the nearest unit responds first. But the battlefield was saturated with enemy electronic jamming. Digital tracking systems that normally display friendly positions in real-time were unreliable. The drones remained unaware of the army unit’s location.
As the Stryker approached, its speed and trajectory resembled patterns the drone’s software associated with enemy forces attempting to seize equipment or prisoners. Patterns of movement encoded during its training. Classifying the vehicle as a high-probability threat, a rapid response was prioritised.
Electronic identification signals meant to confirm friendly status were intermittent under the jamming. Lacking reliable confirmation, the system acted on incomplete data. Within seconds, it fired.
Investigators found no single operator responsible. Instead, disrupted communications, degraded situational awareness, and an algorithm calibrated for speed combined to produce a fatal error. This incident has reignited a debate over delegating lethal decisions to machines — one that will likely continue for several years.
No one was accountable.
8. Epilogue : Keeping Safe
If LLMs introduce uncertainty into software systems, then safety depends not on blind adoption but on disciplined use. The question is not whether AI can be useful—it clearly can—but whether we are deploying it in ways that are proportionate to the risks involved.
The central danger is overestimating what LLMs are. They are powerful tools for language, pattern-matching, and general assistance, but they are not infallible reasoners, and they do not possess judgment, accountability, or an understanding of consequence. The more readily we integrate them into important workflows, the more important it becomes to apply the same rigour we would expect in any other safety-relevant engineering domain.
A safer approach begins with acknowledging that LLMs should not be trusted by default. Trust must be developed, measured, and continuously re-evaluated. In practice, this means identifying hazards, understanding potential losses, and deciding where human oversight remains essential.
8.1 Apply a safety framework
The introduction of an LLM into any system should begin with a structured assessment of risk. The principles of STAMP and STPA are useful here because they force us to think beyond component reliability and instead examine losses, hazards, unsafe controls, and system interactions.
Rather than asking only whether the model works, we should ask what happens when it is wrong, what unsafe actions it could enable, and what feedback and constraints exist to prevent harm. This is especially important in systems where LLMs are connected to external tools, influence human decisions, or operate with partial autonomy.
The easier it becomes to integrate AI into existing systems, the more necessary it becomes to apply deliberate engineering discipline before doing so.
8.2 Develop and measure trust
Trust in an LLM should be treated as conditional, contextual, and dynamic. It is not something established once and then assumed indefinitely. A model may perform well in one domain, poorly in another, and unpredictably in edge cases. Changes in prompts, training, model versions, surrounding tools, or operating environments can all affect behaviour.
For that reason, trust must be earned through observation, validation, and ongoing monitoring. In low-consequence applications, a higher degree of tolerance may be acceptable. In safety-critical domains, the threshold for trust must be far higher. When a model is replaced, updated, or integrated into a new workflow, that trust must be re-established rather than inherited.
We therefore need to move from a world of static testing to one of continual assurance.
8.3 Cross-check outputs and decisions
LLM responses should not be accepted uncritically, particularly in areas where correctness matters. Their outputs should be treated as advisory unless they can be independently verified. In practice, this means cross-checking important responses against trusted sources, established algorithms, or human experts.
Where human expertise is available, it should remain the primary mechanism for validation. Where it is not, secondary checks — such as deterministic software controls, domain-specific validation rules, or even comparison against another model could provide additional protection. None of these measures is perfect, but each can reduce the likelihood that a confident but incorrect response passes unnoticed into action.
Cross-checking is not a sign that the technology has failed. It is an acknowledgement of the kind of technology it is.
8.4 Implement your own guardrails
It is unwise to rely solely on the guardrails provided by AI vendors. Those controls may reduce obvious misuse, but they are designed for general-purpose deployment and cannot account for the specific hazards, values, and tolerances of every application.
Where LLMs are used in real systems, organisations should implement their own constraints around prompts, outputs, permitted actions, escalation paths, and acceptable operating conditions. These controls should be designed with the surrounding system in mind, not just the model in isolation.
Guardrails are most effective when they are external to the model rather than embedded entirely within it. A system should not be trusted to police itself without independent oversight.
8.5 Retain human oversight
Human oversight remains the most important safeguard, particularly where the potential losses are severe. The purpose of oversight is not simply to correct errors after the fact, but to detect deteriorating trustworthiness before harm occurs.
In routine, low-risk workflows, periodic review may be sufficient. In higher-risk settings, review should be more frequent, more structured, and coupled with clear intervention points. In genuinely safety-critical systems, decisions that could endanger life, infrastructure, or public welfare should remain under meaningful human control.
Removing humans from the loop entirely may improve speed and reduce cost, but it also removes judgment, accountability, and the ability to recognise when a situation has drifted beyond what the system can safely handle.
Ultimately, whether we can trust an LLM depends on the consequences of being wrong. Trust is a human judgement, shaped by experience, reputation, and evidence. AI systems should be treated similarly: not as magical replacements for human expertise, but as fallible tools whose use must be constrained by their limitations.
The temptation to integrate LLMs into everything is strong because the gains are immediate and the barriers to entry are low. Yet the risks are equally real. If we deploy these systems carelessly, we will introduce hazards that could have been avoided. If we deploy them carefully, with discipline and humility, we still retain control over the future we are building.
Recommended Reading & Listening
Asimov I. (2058), ”Handbook of Robotics”, 56th Edition.
Asimov I. (1950), “I, Robot”, USA: Gnome Press.
Germain T., Hao K. and Woolf N. (2026), The Interface - “Is AI running modern warfare?”, March 06, BBC Podcast, 37 min. https://bbc.com/audio/play/p0mylrw0.
Leveson, Nancy G. (2011), “Engineering a Safer World: Systems Thinking Applied to Safety”, Cambridge, MA: MIT Press.
Scharre P. (2019), Killer Apps - “The Real Dangers of an AI Arms Race.”, April 16, Foreign Affairs.
https://www.foreignaffairs.com/articles/2019-04-16/killer-apps